
How advertisements and graffiti become dangerous to self-driving cars.
As we place self-driving cars in the real world, these cars need to understand specific real-world environments. But what exactly do they need to understand? In Zagreb and Ljubljana they’ll need to understand that advertisements and graffiti are not real.

Context
The aim of the current analysis is to create a body of knowledge to help data scientists tailor the MSeg1080_RVC model* to the urban environment of Zagreb, Croatia and Ljubljana, Slovenia.
With this body of knowledge, data scientists training self-driving cars for Zagreb or Ljubljana with the MSeg1080_RVC model can:
- frame their problem-solution better;
- reduce the burden of data collection, labeling and processing;
- formulate a more suited modeling process;
- asses the real-world relevance of the model’s performance*.
Ultimately, this body of knowledge helps data scientists save time, resources, and create a more usable and safer end-product.
Approach
The core focus is to gain actionable insights that directly impact the data collection and labeling decisions data scientists take while working with the MSeg1080_RVC segmentation model.
To gain such insights, a custom qualitative research method was applied in Zagreb and Ljubljana over a two week period in November, 2022.
This custom method generates a systematic understanding of local environments specifically adapted to the field of image recognition.
The results save time and resources by giving direction to technical solutions.
Results
Tram advertisements
19 tram lines running through Zagreb connect different parts of the city. In most cases, these trams display advertisements on their sides. The visual content of these advertisements vary from simple words to pictures of babies with tennis rackets. While eye catching to humans, a number of these advertisements confused the model.


In the above image, the tram’s advertisement covers and obscures most of the tram. Only the front part of the tram is recognized (as train and bus), while most of the remaining parts are recognized as “fence”. Similar faulty predictions on tram advertisements can be seen in the images below.




However, the model doesn’t always make faulty predictions on trams, as seen in the two images below (if train or bus is considered the correct label for tram). In the left image, a tram with pictures of people is recognized simply as a train, as it should be. In the right image, the tram displays no advertisements, which is much more easily recognized by the model.

Billboards
Billboards can be found all through Zagreb’s and Ljubljana’s city centers. At times, these billboards stand right next to the road while at other times they are on poles high above the road. They portray a wide variety of scenes, often with people and cars. Similar to the advertisements on trams as discussed above, the model often fails to distinguish between reality and fiction here as well.


In the above image, a billboard displaying an advertisement of a car hangs close to the road. However, the model labels the image of the car as a car in itself. This difference between reality and fiction would have easily been picked up on by a human (i.e. seeing the border of the billboard or the text surrounding the car). Similar faulty predictions on billboards can be seen in the images below.



Of course, the images above are taken close to the billboards. This makes it understandably harder to distinguish between reality and fiction, even for humans.
When the images contain the surroundings of the billboards, the model has a much easier time labeling them as a billboard instead of its content. This can be seen in the images below. Nevertheless, in many cases in reality, billboards are placed close to roads which would obscure the surroundings.




While the surroundings of billboards greatly aid the model’s performance, this is not always the case, as can be seen in the below image of a billboard with a dog.


Graffiti
Similar to the tram advertisements and billboards, graffiti also often depicts diverse scenes with people right next to the road. Here as well, the model isn’t always able to distinguish between reality and fiction. An example of this can be seen in the picture below.


The above image clearly depicts drawn figures, not real people. Nevertheless, the model (partially) labels these figures as a person. Similar to the above cases with billboards, the picture is taken up close without much context. Even so, the widely non-realistic style (as opposed to the realistic style of billboards) should be enough to distinguish between reality and fiction. More examples of faulty predictions on graffiti can be seen in the images below.




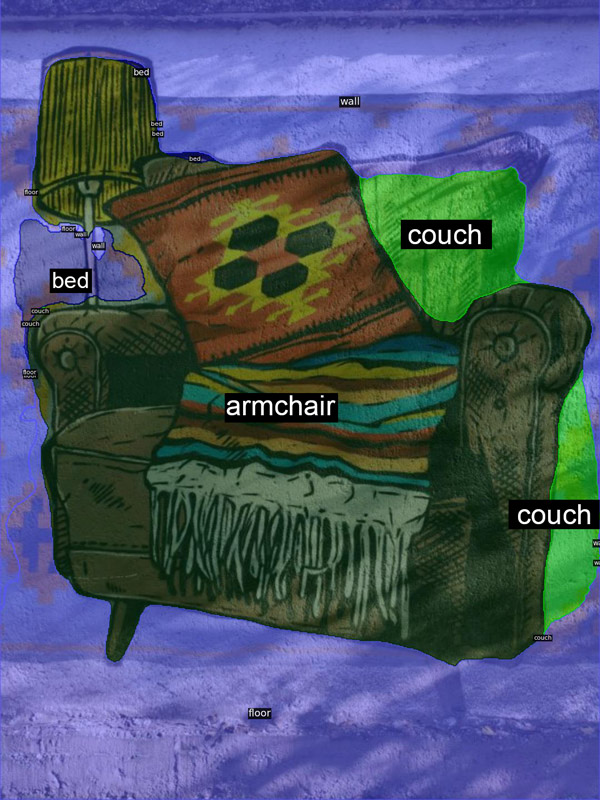
When the surroundings are added to the images, the model performs much better, as seen in the image below.

While often times the predictions make sense when surroundings are added, this is not always the case. For instance, the image of abstract graffiti below is labeled as a truck, even with the context of a building around it.


Finally, in Zagreb, an interesting street art project called Pimp My Pump resulted in water pumps next to the roads being decorated with graffiti (often of famous people). While the visual appearance of the pumps completely changed, the model was still very good labeling the pumps as “fire hydrants”.




Insights
Overall, the MSeg1080_RVC model performs very well. Buildings, people, vegetation, cars, etc. were easily detected by the model in the current analysis. The accuracy and robustness of the model are truly impressive.
Nevertheless, several scenario’s from Zagreb and Ljubljana resulted in faulty predictions which could lead to dangerous situations in real-world contexts. To prevent these faulty predictions, three recommendations are provided:
1. Train the model to recognize visual advertisement styles
The model performs relatively well on advertisements and billboards when their surroundings are visible. However, in reality, these surroundings might not always be entirely visible for the camera’s of self-driving cars: billboards are placed on walls right next to roads, while trams with advertisements often narrowly pass cars.
To make the model more robust, it is recommended to not only rely on the surroundings of advertisements and billboards, but also on their visual styles. For instance, the large slogans and often smiling, ecstatic people could provide clues to the model that the advertisements are fiction.
2. Train the model to recognize visual graffiti styles
While advertisements often contain realistic pictures of people and cars, graffiti usually has entirely non-realistic visual styles (though not always). Training the model to recognize non-realistic styles could help the model distinguish between reality and fiction when no surroundings are visible.
3. Train the model to understand advertisements and graffiti in motion.
Of course, self-driving cars are usually in motion. This provides an opportunity where the model registers advertisements and graffiti from afar while their surroundings are still visible. Once the cars get closer and the surroundings disappear, the model could rely on previous detections to understand it is the same advertisements or graffiti. A combination between this recommendation and the previous two seems ideal.
*Runner up of the 2022 Robust Vision Segmentation Challenge on the Cityscapes’ self-driving car dataset. Overall, a state of the art segmentation model useful for self-driving cars that is publicly available. In a previous version of this post the FAN_NV_RVC model was mistakenly referenced.